JetBrains IDEをご利用の皆様はAI Assistantを活用していますか?
AI Assistantは、IDEが解析済みのインデックス情報を利用することでソースコードのスキャンを減らし、少ないトークンで高精度な開発ワークフローを実現することができます。
とはいえ、多用しているとAIクレジットの消費が気になるものです。
そこで試していただきたいのが、ローカルモデルの活用です。AI AssistantはGPT、Gemini、ClaudeやGrokなどの著名なモデルを自由に選択できるだけでなく、LM StudioやOllamaといったLLMを手元で手軽に動かせるツールと組み合わせることで、無料でAIを使ったワークフローを実現できます。
ここではLM Studioを使った方法をご紹介します。
LM Studioのインストール
LM Studioは、各種LLMのダウンロード・実行・対話型チャットインターフェース、そして言語モデルサーバの機能を備えた統合ツールです。macOS、Windows、Linuxに各アーキテクチャ別のパッケージ(macOSのIntelアーキテクチャを除く)が提供されており、商用、非商用を問わず無償で利用できます。
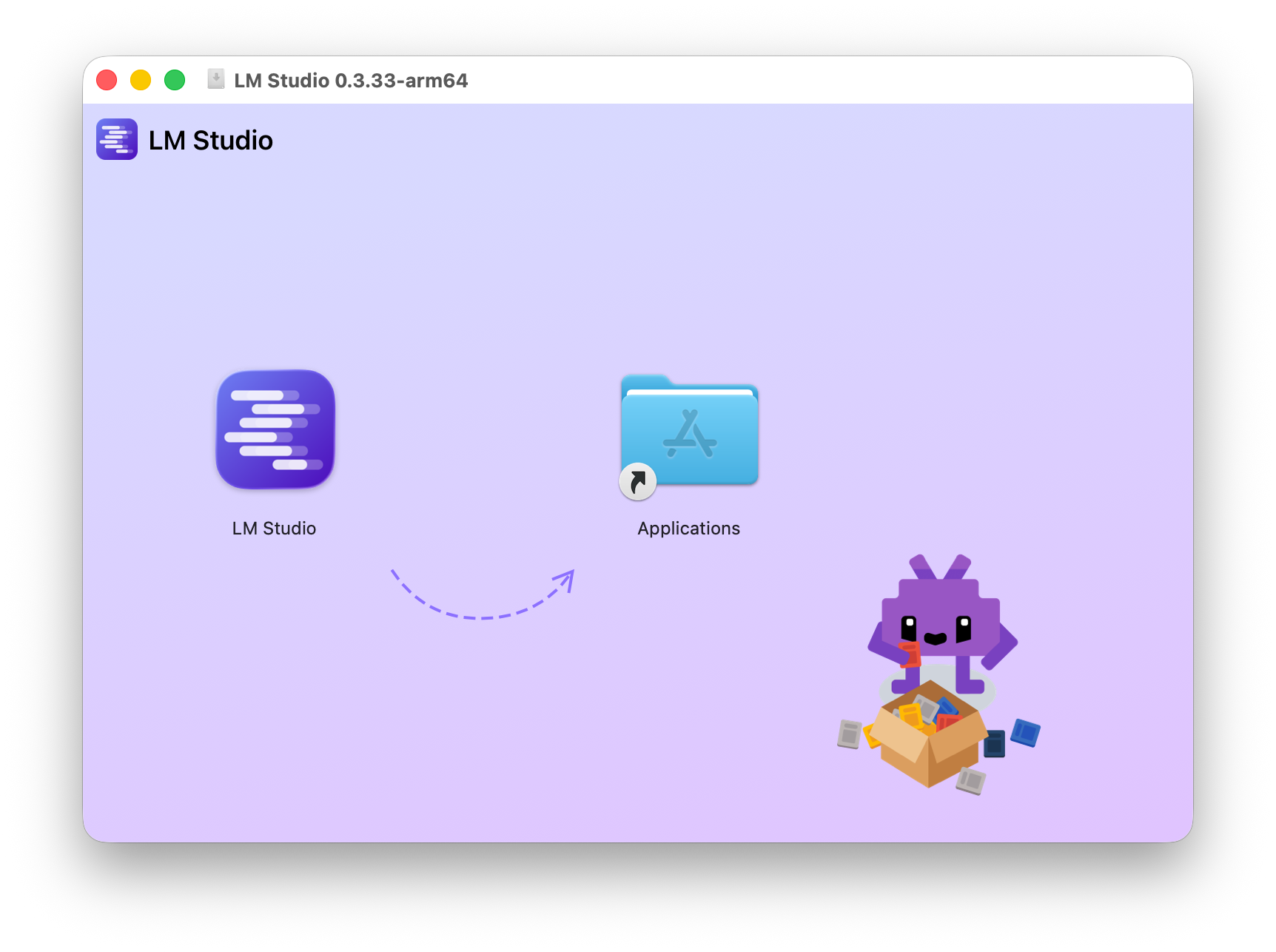
インストールは簡単で、例えばmacOSの場合はアプリケーションフォルダへドラッグ&ドロップするだけで完了します。
初回起動時は簡単なセットアップを行います。
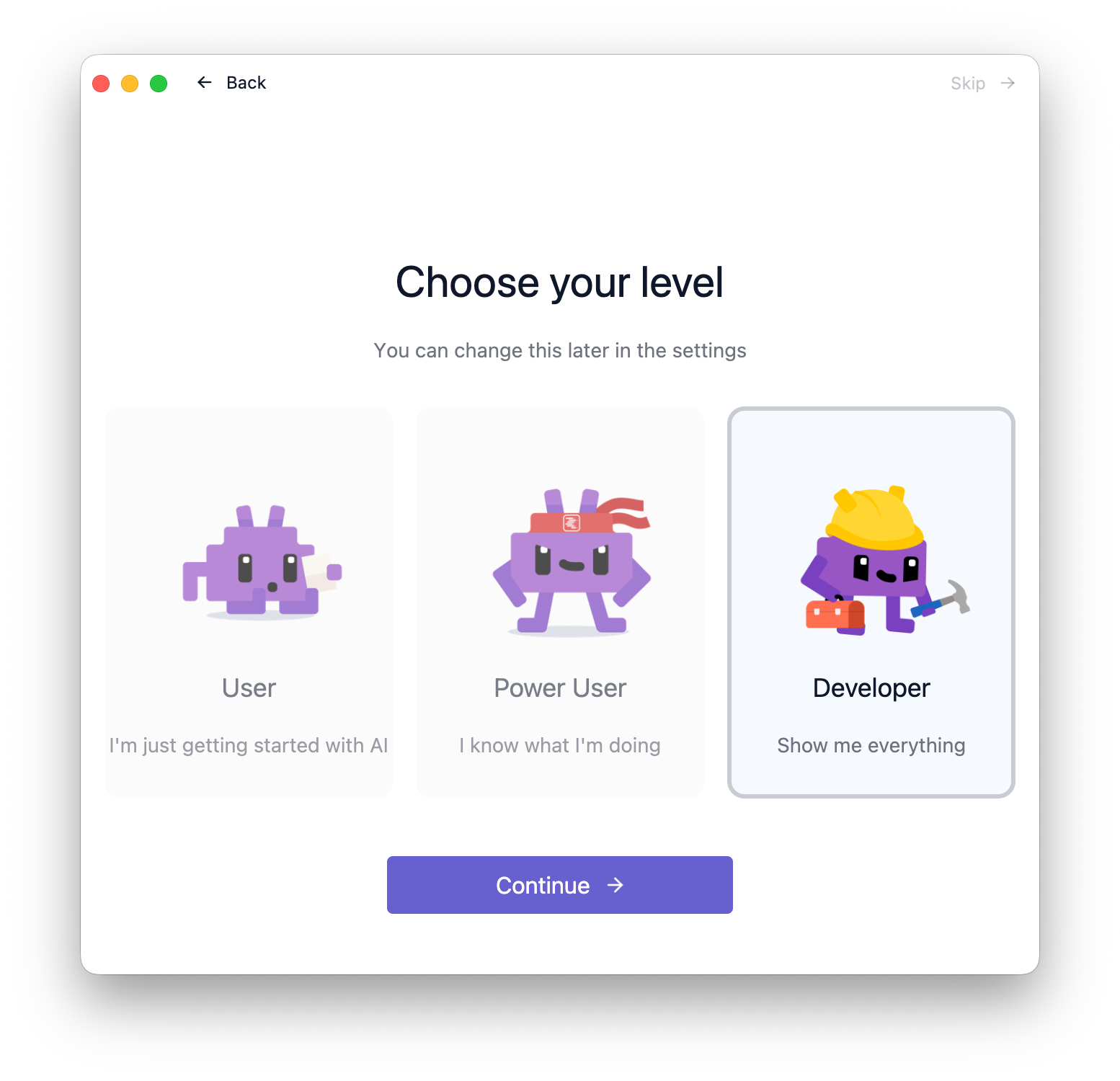
ユーザーのレベルに応じてUIの詳細度が変わる仕組みになっています。プログラマーであれば”Developer”で良いでしょう。このレベルは後からでも1クリックで切り換えられます。
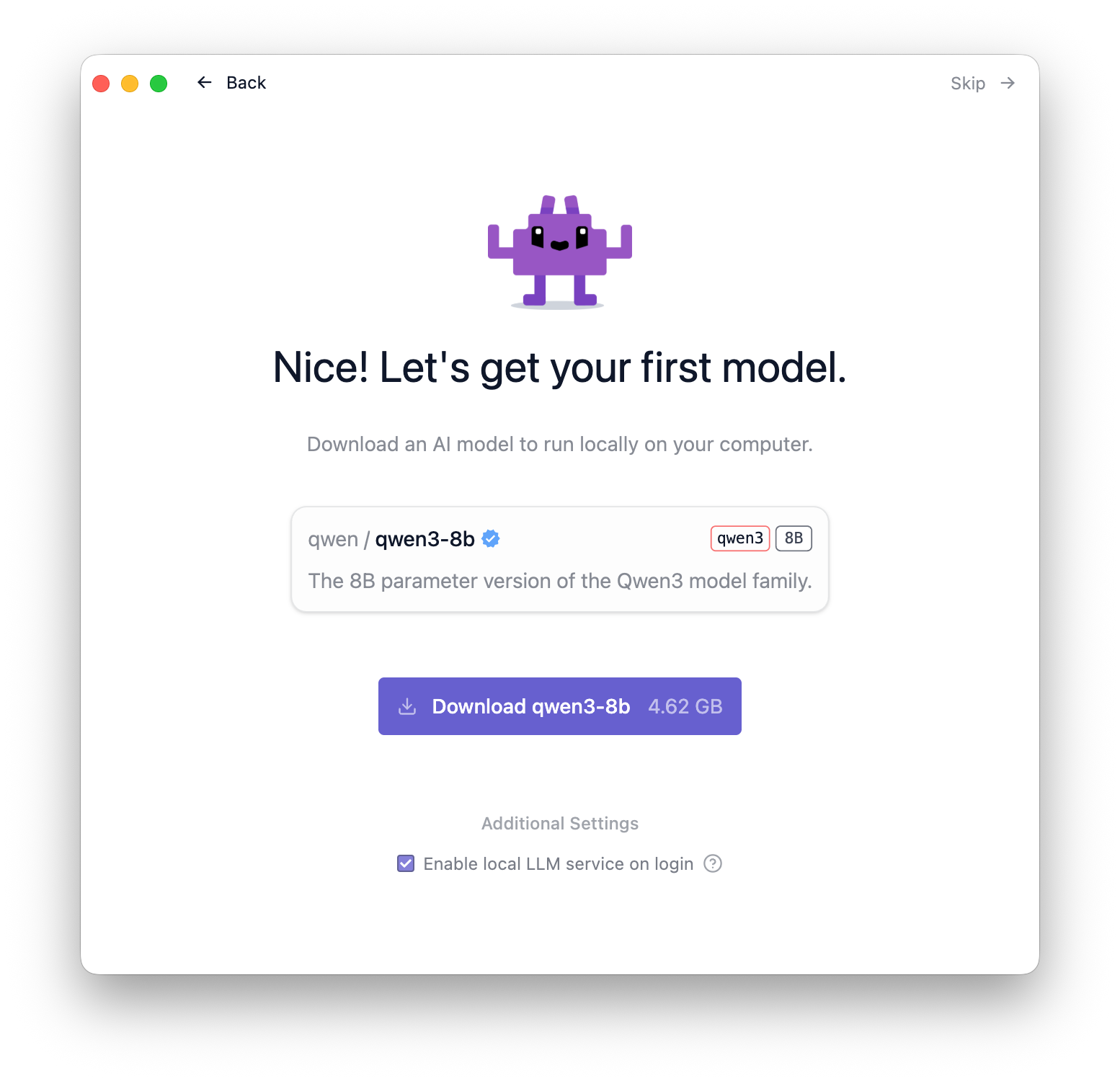
手始めにお勧めのモデルのダウンロードが行えます。ダウンロードボタンを押して進めてください。
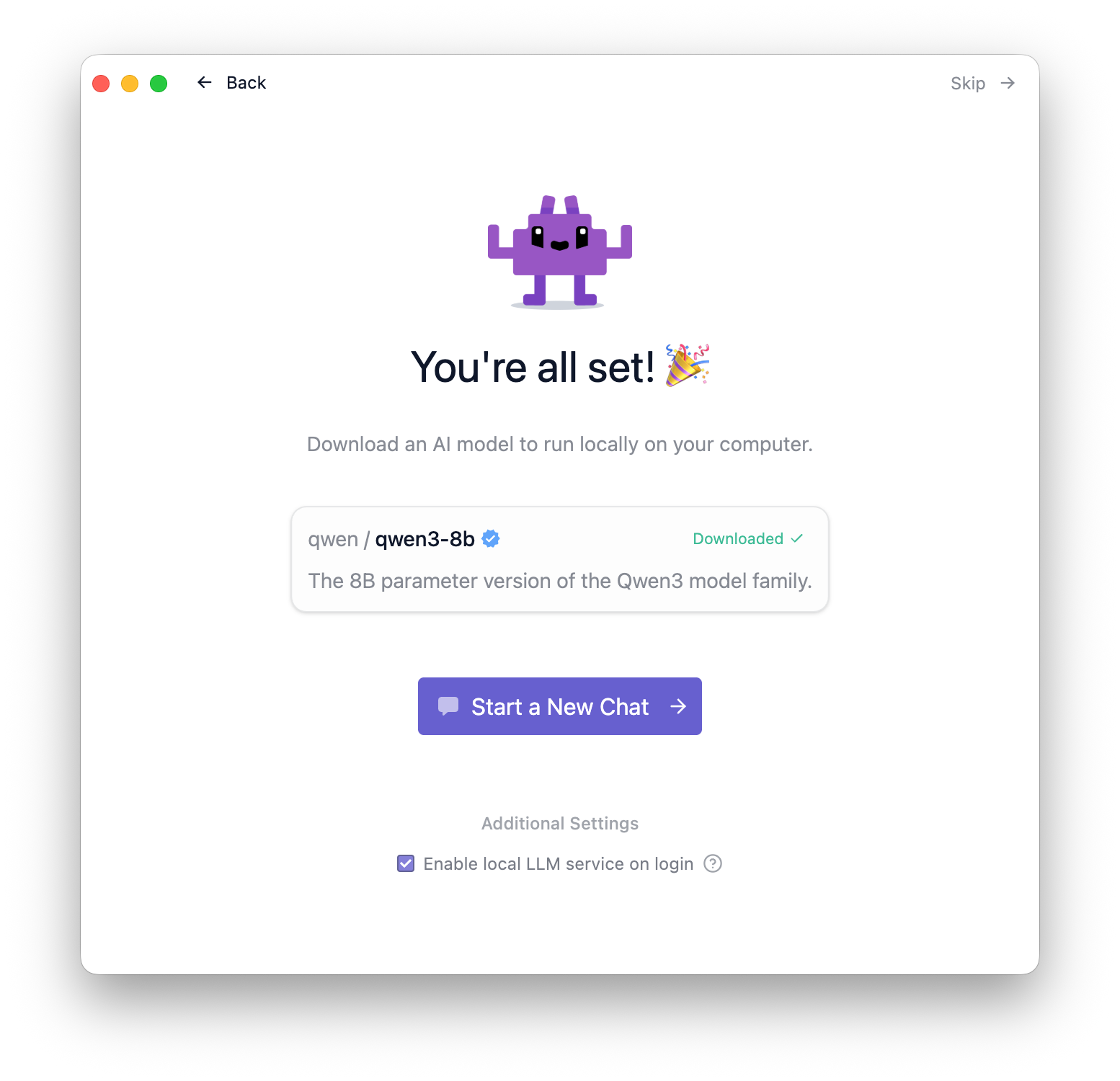
ダウンロードが完了したら”Start a New Chat”より、いよいよローカルLLMの動作確認を行えます。
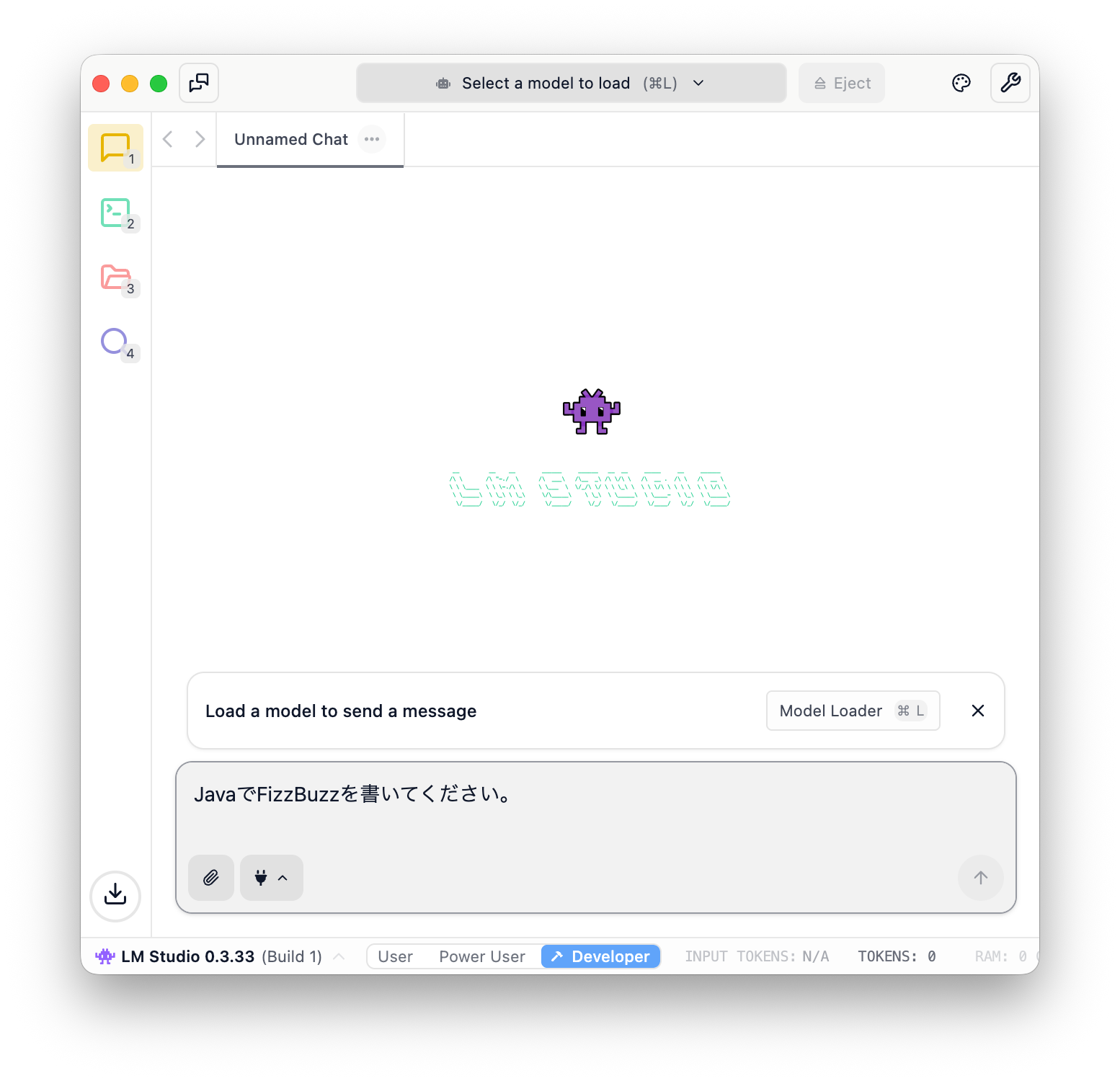
プロンプトを書くとモデルのロードを促すメッセージが現れますので”Model Loader”を押します。
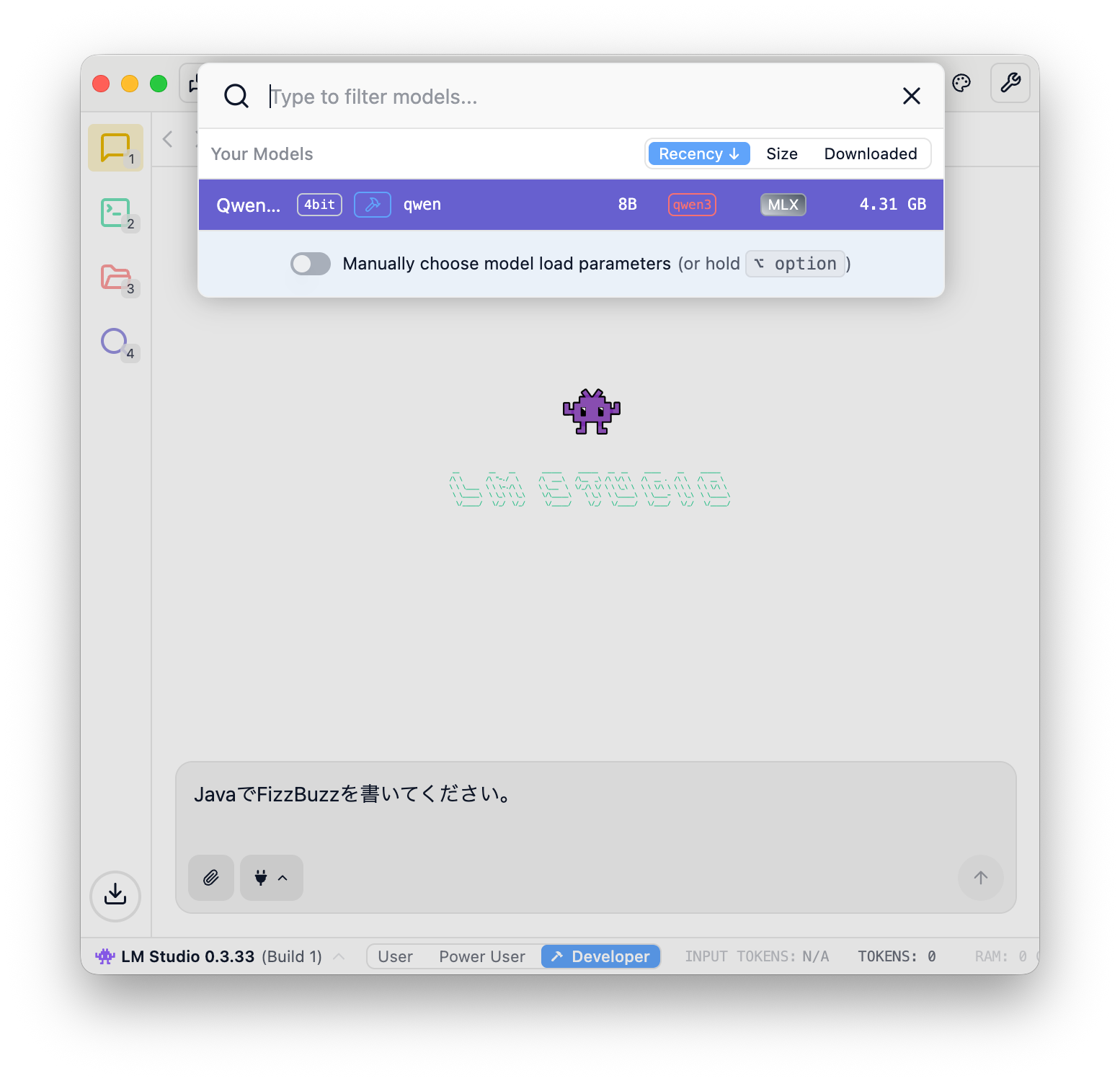
ここでは最初にダウンロードしたQwen3-8bを選択してみます。
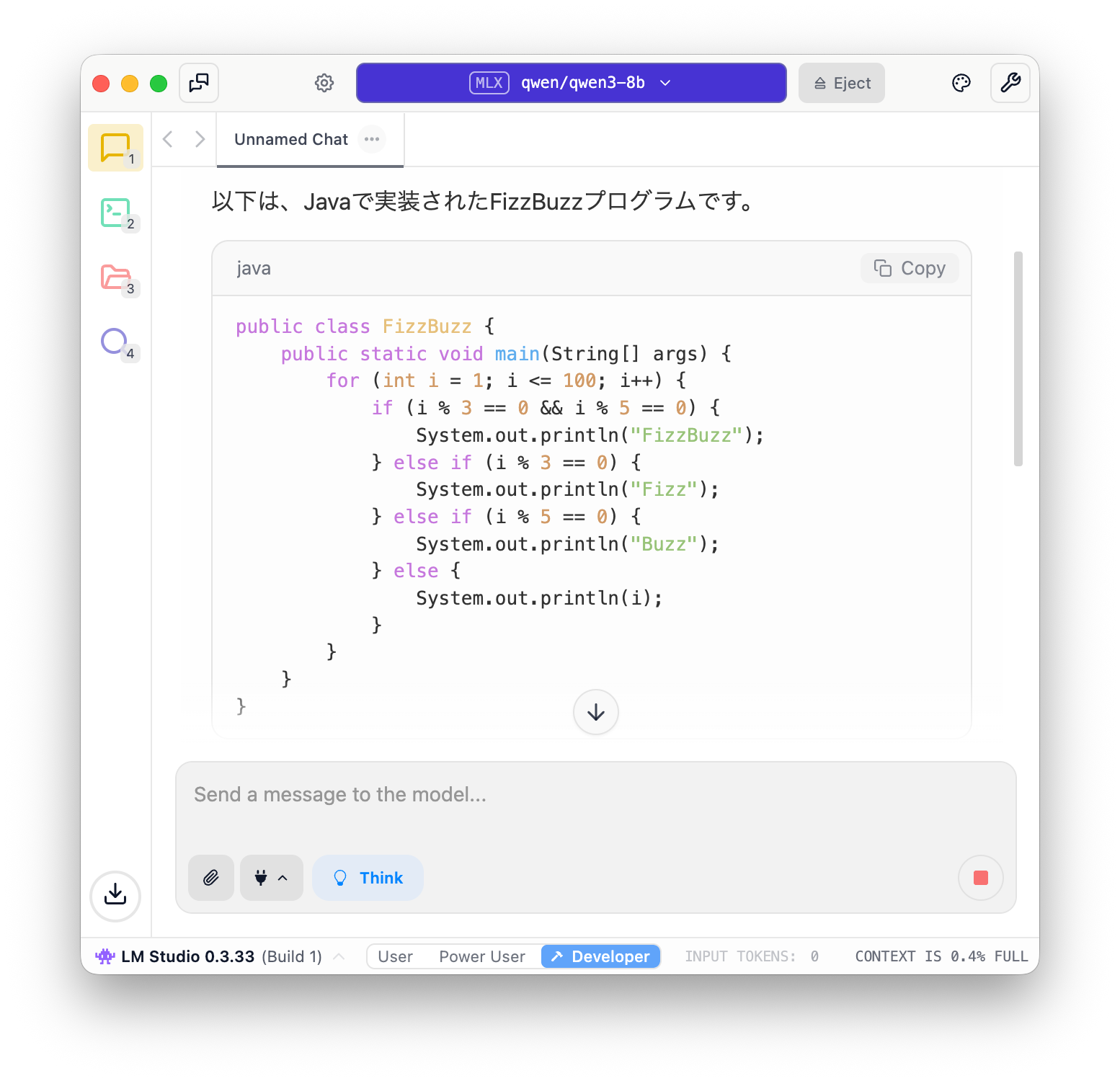
モデルのロードが完了し、プロンプトを投げると、結果が返ってきます。問題無く動作しているようです。
LM Studioのサーバを起動する
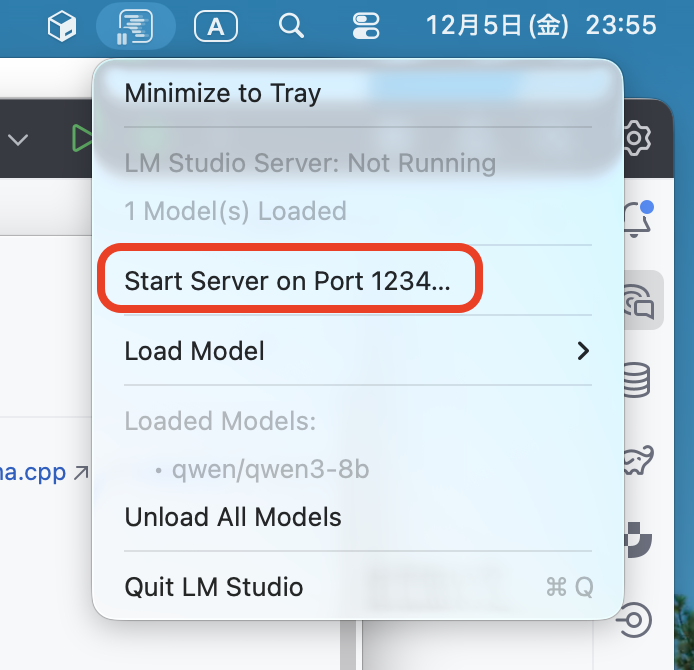
次に、LM Studioでロードしたモデルを他のアプリケーションから利用できるよう、サーバを起動します。
macOSではツールメニューから”Start Server on Port 1234…”を選択するだけ起動できます。
AI Assistantの設定
AI AssistantからLM Studioを利用する設定も簡単です。
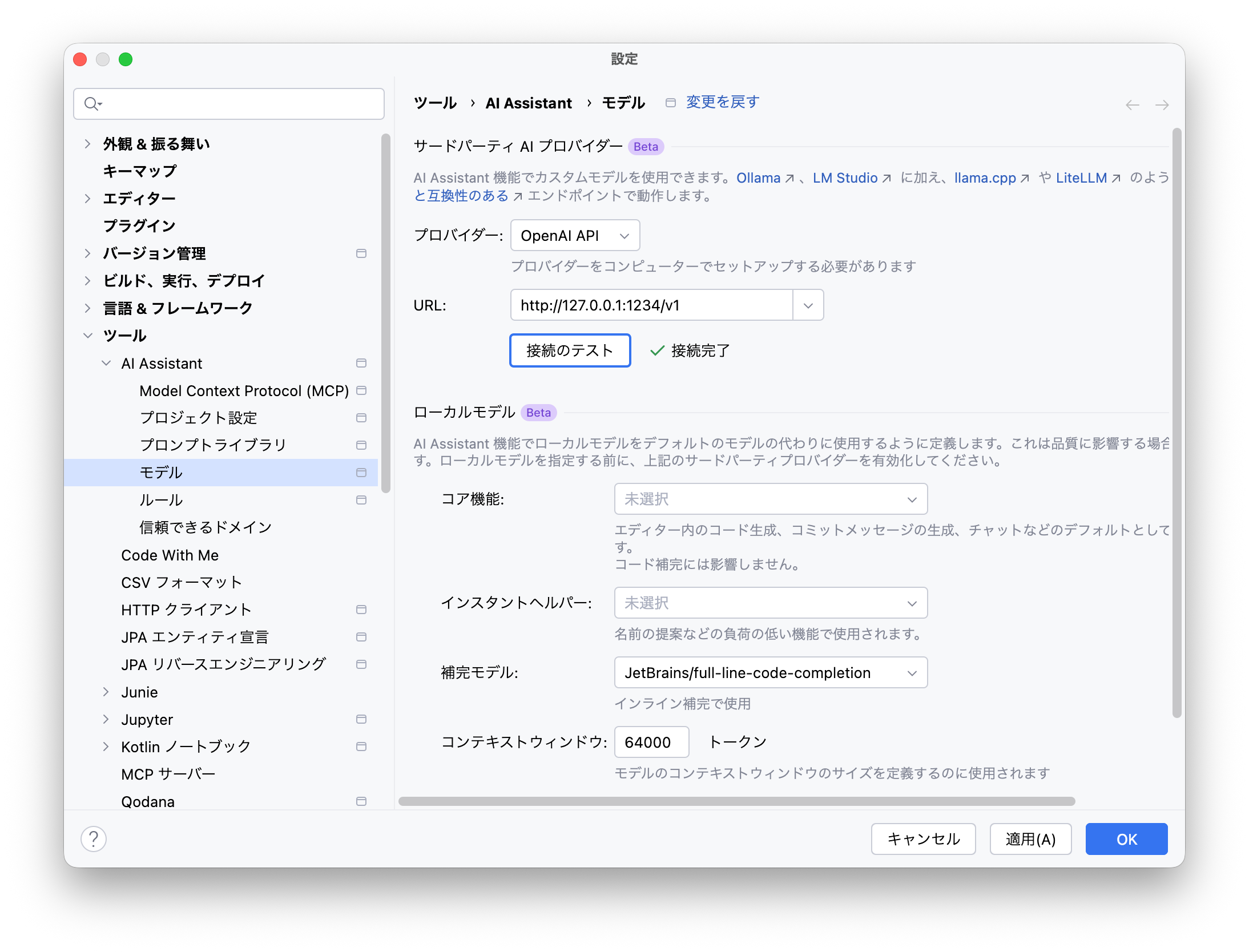
IDEの設定画面を開き、[ツール]→[AI Assistant]→[モデル]→[サードパーティAIプロバイダー]にて、”OpenAI API”(*)を選択します。
* LM Studioを選択するとチャットUIでモデルを選択できないことがあります
“URL:” 欄には”http://localhost:1234/v1″を入力します。このURLはメニューバーのLM Studioのアイコンより”Copy LLM Server Base URL”でクリップボードにコピーして貼り付けることもできます。
URLの設定まで終わったら[接続のテスト]を押して、[接続完了]となるのを確認しましょう。
AI Assistantの実行
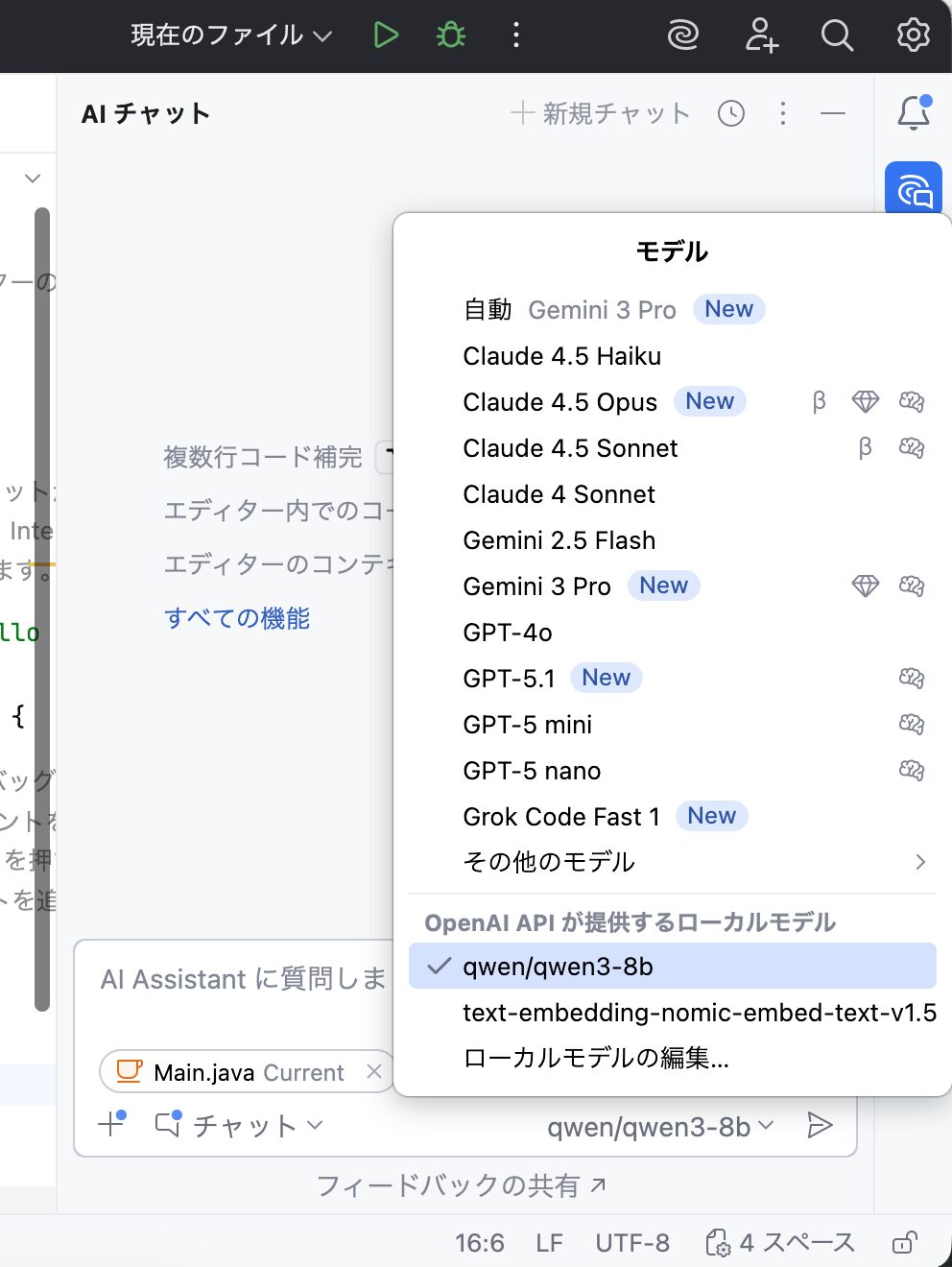
いよいよAI Assistantで使用するモデルとしてLM Studioを指定します。
AI Assistantのチャットインターフェース右下のモデル選択欄で”OpenAI APIが提供するモデル”より、ローカルで動作するモデルが選べるようになっているのが確認できます。
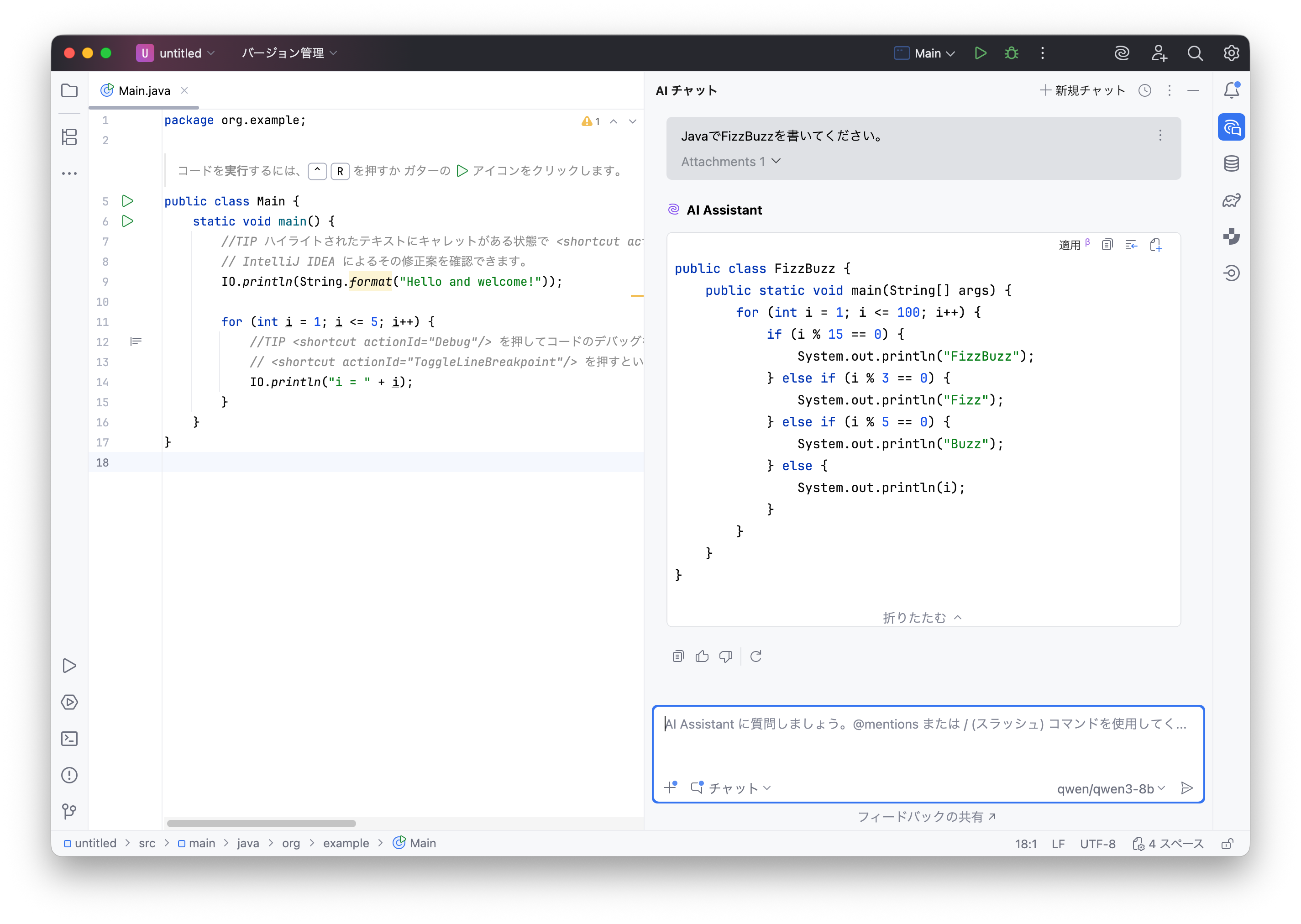
一方、リモートモデルではGPT-5.1-Codexで61秒、GPT-5.1-Codex-Miniでは65秒でした。(計測はどれも1回のみ)
もちろんどの出力もFizzBuzzのプログラムとして正常に動作しました。
動作速度や精度は、利用するモデルの特性や、お手持ちのマシンのメモリ・GPU・CPUによって大きく変化しますが、ローカルLLMでも実用上大きく見劣りすることはなさそうです。普段使いはローカルLLM、複数のバリエーションを高速に試したいときはリモートLLM、といった形で使い分けも可能です。ぜひご活用ください。