
PHPカンファレンス小田原 2026ではたくさんの方にブースにお越し頂きありがとうございました。ありがとうございます。
ブースでお願いいたしましたアンケート結果を集計いたしましたので公表させていただきます。今後の開発環境の方針などの参考にしていただければ幸いです。
投稿者: yusuke
MCPサーバー機能を使い JetBrains IDE外のAIも賢くする #JetBrainsIDEテクニック #jbtips

AI AssistantやJunie の強み
LLMを基盤とする確率ベースで動作するAIにコーディングを依頼すると、存在しないシンボルを書いたり、文法ミスを含むコードを書いたりすることがしばしばあります。こうした問題は、テストを実行するまで見つからないことも少なくありません。
そこで力を発揮するのがJetBrains IDEの静的解析機能です。JetBrains IDEはコードだけでなく、フレームワークの設定ファイルやテンプレート、各種構成ファイルまで含めて関係性を理解し、プロジェクト全体を横断して解析できます。
そのためAIは、テストを実行せずとも誤りに気づくことができ、より少ないトークンでより賢く動けるようになります。
さらに、この強みはコード生成だけにとどまりません。シンボル参照や依存関係を正確にたどれるため、AIはリファクタリングやデッドコードの発見・削除にも取り組みやすくなります。
そして、これらのJetBrains IDEの力を最初から活用できるように設計されているのが、AI AssistantやJunieです。両者の強みは、単にAIモデルの性能だけではなく、IDEの解析力や実行環境を前提に賢く動けることにあります。
外部ツールにも広がるJetBrains IDEの力
最近では、JetBrainsのAI Assistantだけでなく、CodexやClaude Codeなど、複数のAIツールを併用している方も多いのではないでしょうか。そんなときに役立つのが、JetBrains IDEのMCPサーバー機能です。
この機能を使えば、外部のAIツールからもJetBrains IDEの機能を利用できるようになります。
設定は簡単です。[設定] → [ツール] → [MCP サーバー] から [MCP サーバーの有効化] にチェックを入れ、各AIツール向けの [自動構成] を使うか、[手動クライアント構成] から設定用JSONをコピーして適用するだけです。
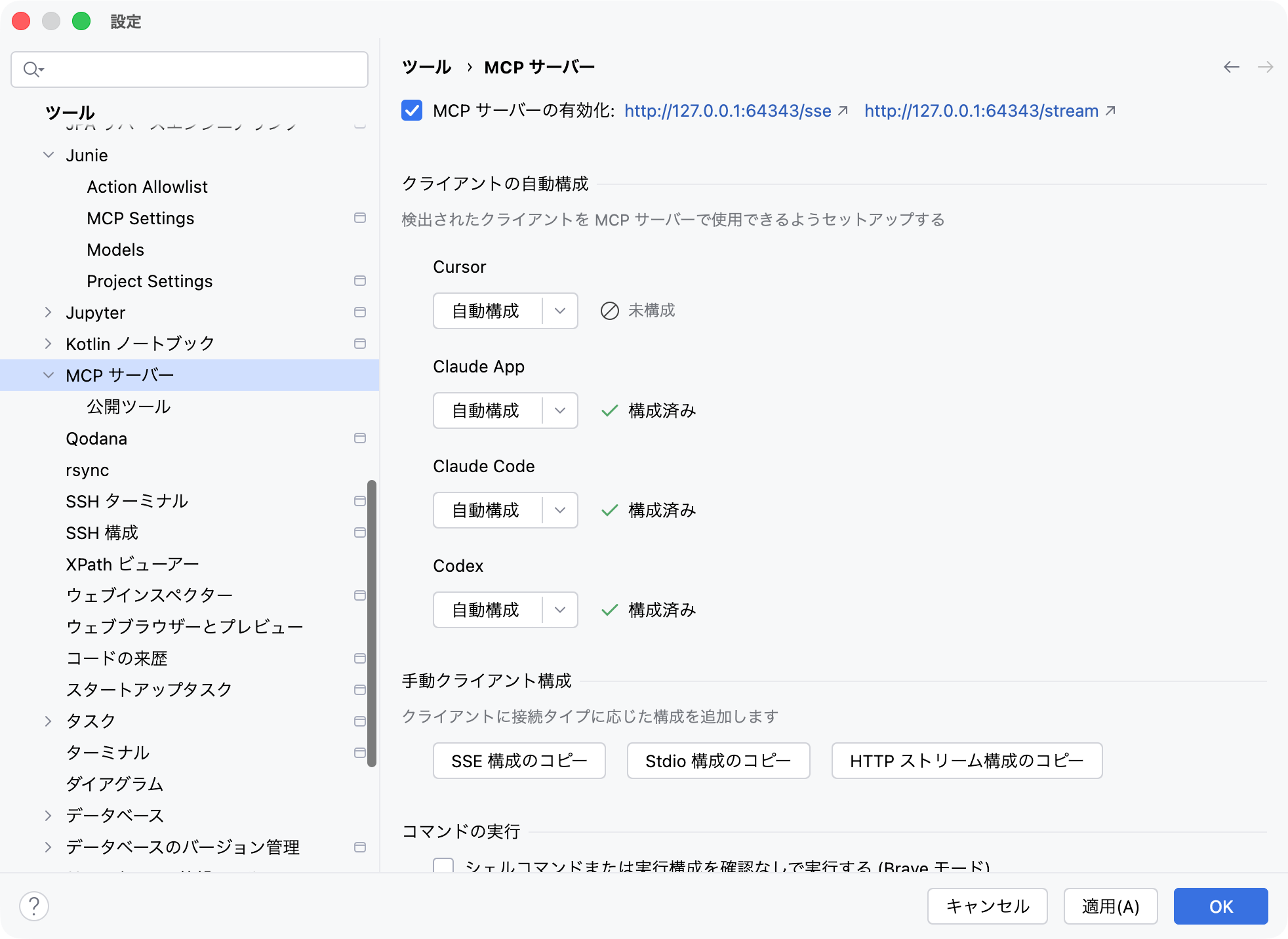
もともとJetBrains IDEの機能を活用する前提で設計されているAI AssistantやJunieと異なり、外部のAIツールでは、MCPサーバー機能を積極的に利用するよう、CLAUDE.mdやAGENTS.mdで適切にプロンプトを与える必要もありますのでご注意ください。
JetBrains IDEがMCPサーバーで提供している機能は以下のページでご確認いただけます。
IntelliJ IDEA Help – Integrated tools – MCP Server
AIが賢く働ける環境を作る
これから重要になるのは、どのAIを使うではでなく、そのAIにどんな開発環境を与えるかです。JetBrains IDEのMCPサーバー機能は、これからの開発体験を支える中核的な仕組みだといえるのではないでしょうか。
PHPerKaigi 2026アンケート集計結果 – 利用言語や利用AIなど #PHPerKaigi

PHPerKaigi 2026ではたくさんの方にブースにお越し頂きありがとうございました。ありがとうございます。
ブースでお願いいたしましたアンケート結果を集計いたしましたので公表させていただきます。今後の開発環境の方針などの参考にしていただければ幸いです。
オンラインセミナー 〜最新JavaとAI、Java開発環境〜 3月27日(金) 15:00〜

JetBrains社の日本の総代理店である株式会社サムライズムがJavaの最新動向を紹介するオンラインセミナーを開催します。
概要
Javaは17、21、25とバージョンを重ねるにつれて、生産性の向上につながる文法の改善が数多く導入されてきました。本セミナーでは、代表的な新しい文法要素を取り上げて説明し、デファクトスタンダードのJava開発環境であるIntelliJ IDEAがそれらの導入をどのように支援するのかを解説します。
さらに、IntelliJ IDEAの最新のAI関連機能についても取り上げ、コード生成や開発支援がどのように進化しているのかを紹介します。
デモでは実際にIntelliJ IDEAを使いながら機能をご覧頂き、最後にQ&Aの時間を設けます。
日程
2026年3月27日(金)15:00〜16:00
場所
オンライン(Zoom)
参加用のURLはご登録頂いた方に個別にお知らせ致します。
主な内容
- JetBrains / IntelliJ IDEAの紹介
- Javaの最新機能とIntelliJ IDEAの関連機能
- IntelliJ IDEAの最新AIアップデート
- デモ
- Q&A
対象者
- Java開発者
- IntelliJ IDEAを利用している、または導入を検討しているソフトウェア開発者
- Javaの最新機能や開発ツールのアップデートを知りたい方
- AIを活用した開発支援機能に興味のあるソフトウェア開発者
講演者
- 山本裕介
株式会社サムライズム代表。Javaチャンピオン。IntelliJ IDEAを愛して20年以上のOSSデベロッパ。代表作にTwitter4J、侍、BusinessCalendar4Jなど。主な著書にプロになるJava。

株式会社サムライズム – Azul Systems社の製品を取扱開始

![]()
株式会社サムライズム – Azul Systems社の製品を取扱開始
株式会社サムライズム(本社:東京都、代表取締役:山本 裕介)は、JavaプラットフォームのリーディングカンパニーであるAzul Systems社の製品の取扱を開始したことをお知らせいたします。
Azul Systems
https://www.azul.com/ja/
株式会社サムライズム
https://samuraismcom.samuraism.com/
背景
クラウドコンピューティングや仮想化技術、AIの普及により、システムの開発・展開は大きく効率化しました。一方で、運用環境の高度化・複雑化に伴い、セキュリティリスクの増大や運用管理コストの上昇といった課題が顕在化しています。
Azul Systems社の製品を導入することで、Javaアプリケーションを変更することなく長期的なJVMサポートを受けられるほか、パフォーマンス向上によるコンテナ稼働数の最適化、さらに既知の脆弱性の実際の悪用可能性を可視化することが可能になります。
これにより、システム全体の運用コストを抑制するとともに、サイバー攻撃に対する防御力の強化に貢献します。
Azul Systems社について
Azul Systems社は2002年に設立されたJavaプラットフォームのリーディングカンパニーで、米国カリフォルニア州サニーベールに本社を構えています。Fortune 500企業の25%以上を含む世界中の企業に採用されており、高性能かつ高信頼性のJavaランタイムおよびプラットフォームソリューションを提供しています。
Webサイト: https://www.azul.com/ja/
住所:
385 Moffett Park Dr, Suite 115
Sunnyvale, CA 94089
株式会社サムライズムについて
株式会社サムライズムは、オープンソース、Web、API技術を中核としたソフトウェアソリューションプロバイダです。
国内トップクラスのソフトウェア導入支援実績とAPI活用ノウハウを活かし、企業のDX推進を支援する製品およびサービスを提供しています。
株式会社サムライズム
英文表記: Samuraism
代表者: 山本 裕介
設立: 2013年3月
Webサイト: https://samuraismcom.samuraism.com/
Twitter: @samuraism
本リリースに関するお問い合わせ
株式会社サムライズム 代表 山本 裕介
電話: 03-4405-5117
メール:
株式会社サムライズム – Azul
![]()
BuriKaigi 2026アンケート集計結果 – 利用言語や利用AIなど #BuriKaigi

BuriKaigi 2026ではたくさんの方にブースにお越し頂きありがとうございました。ありがとうございます。
ブースでお願いいたしましたアンケート結果を集計いたしましたので公表させていただきます。今後の開発環境の方針などの参考にしていただければ幸いです。
BuriKaigi 2026 に協賛いたします #BuriKaigi

株式会社サムライズムは2026年1月9日〜10日に富山国際会議場にて開催されるBuriKaigi 2026に協賛いたします。
サムライズムのブースではJetBrains IDEをBacklogと連携させるBacklog Integration Plugin for JetBrains IDEs、AI Assistant、に加え弊社の生産性向上製品#CIclone、JetBrains IDEに強力なブラウザ機能を追加する#TamaCatなどもご紹介いたします。
ステッカーやピンバッジなどのグッズも配付いたしますので是非お越しください。
AI AssistantをサードパーティーAIプロバイダー と手持ちのAPIキーで利用する (BYOK – Bring Your Own Key) #JetBrainsIDEテクニック #jbtips

AI Assistantとモデル
JetBrains IDEのAI Assistantは一つの契約でGemini/GPT/Claudeなど様々なモデルを比較的手軽に利用できる点が魅力です。一方で、組織によってはIDEとは別にAIのプロバイダーとすでに契約しており、そちらを活用したいというケースも多いのではないでしょうか。
実際に、既契約のAIツールをターミナルや専用クライアントを通じて利用しつつ、コードレビューやリファクタリングはJetBrains IDE上で行っているという話も良く耳にします。
そこで、JetBrains IDE 2025.3.1から登場したのがBYOK(Bring Your Own Key)です。
AI AsssisantとBYOK(Bring Your Own Key)
AI AssistantのBYOK機能を使うと、既存のAIプロバイダーの契約で発行されるAPIキーを使ってAI AssistantによるIDEとの密な連携を実現できます。この場合、JetBrainsのAI Asssitantの追加クレジットは不要です。
現時点で、BYOKはAnthropicとOpenAIまたはOpenAI互換APIでご利用いただけます。
サードパーティーAIプロバイダー(BYOK)の設定
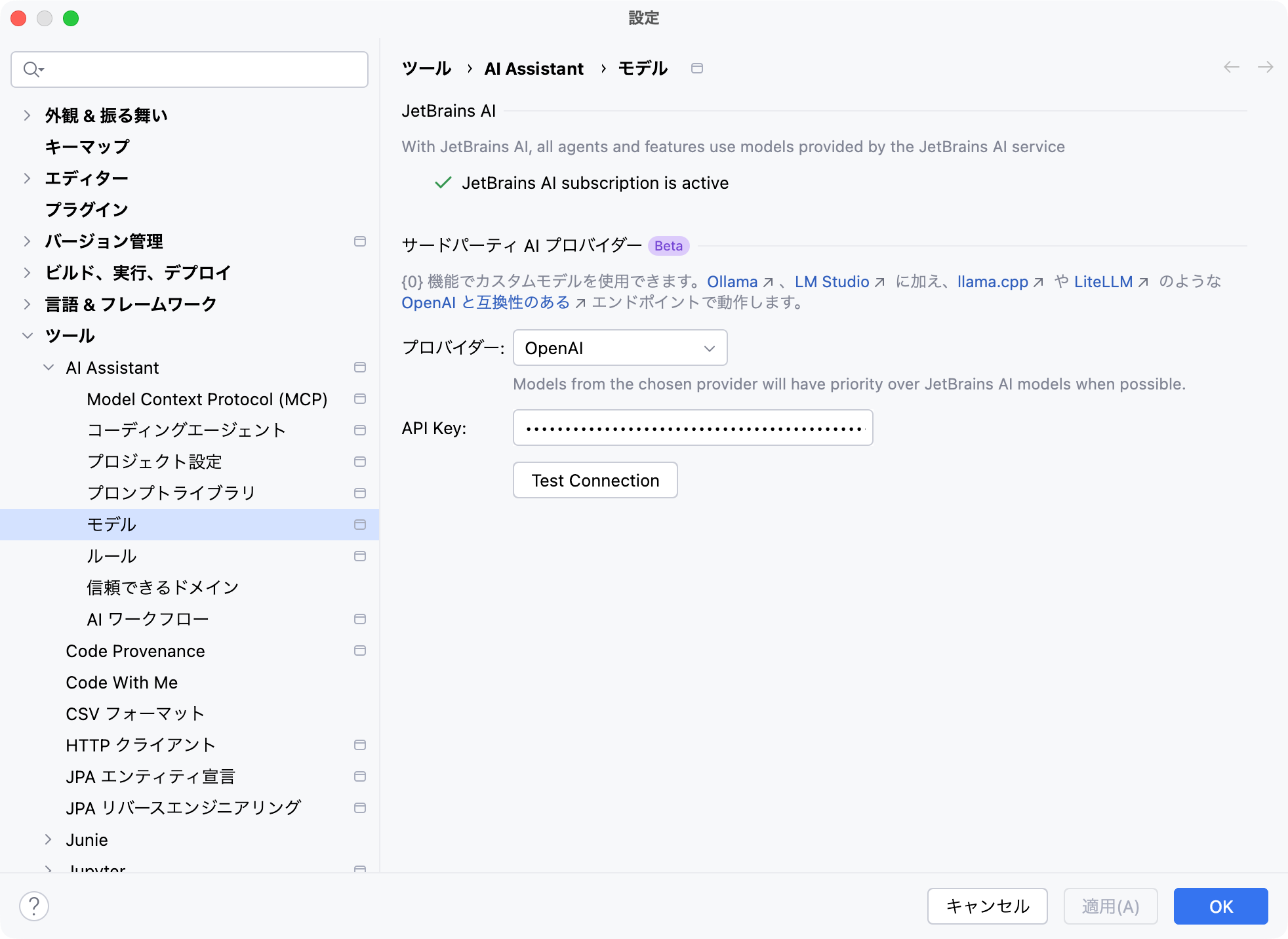
サードパーティーAIプロバイダーの設定は簡単です。
IDEの[設定]>[ツール]>[AI Assistant]>[モデル]>[サードパーティーAIプロバイダー]>より[プロバイダー]と[API Key]を指定するだけで完了します。
サードパーティーAIプロバイダーの利用
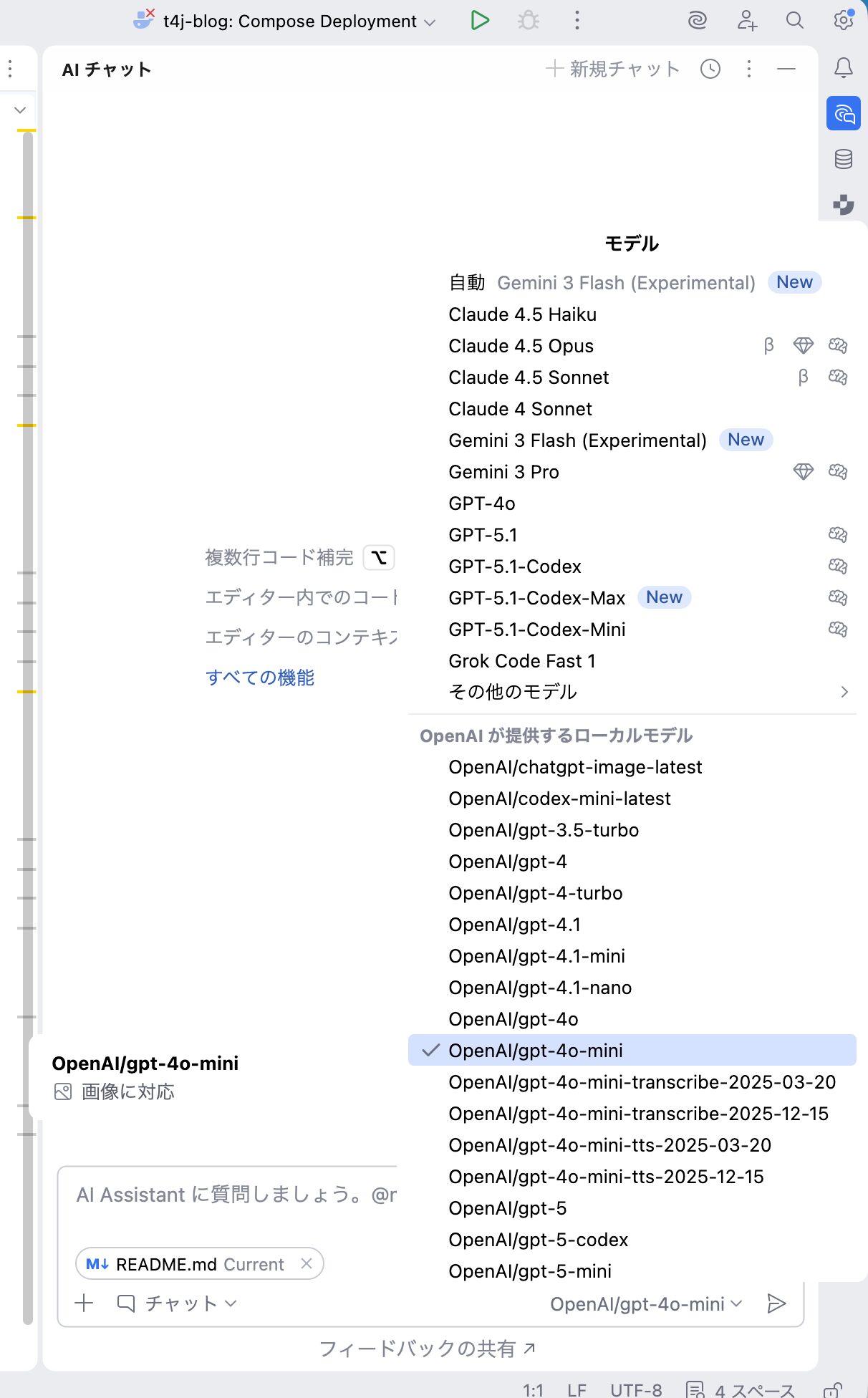
設定が完了したら、AIチャットツールウィンドウ右下のモデル選択欄より[OpenAIが提供するローカルモデル](ローカルモデル・・・は正確な表現ではないと思いますが)などを指定し、任意のプロンプトを入力してください。
AI Pro/UltimateとBYOK、どちらを選ぶべき?
JetBrainsのAI Pro/Ultimateは1つの契約で様々なモデルを選択することができることや、追加クレジットを組織内で共有できることなどがメリットです。その一方で、基本的にJetBrains IDEの外では利用できないという制約もあります。
BYOKでは、すでに契約しているAIプロバイダーを無駄にすることなく、JetBrains IDEとAI Assistantの生産性をそのまま享受できます。
どちらかが一方的に優れているというものではないため、組織やプロジェクトの状況に合わせてご検討ください。
LM Studioを使ったAIクレジットを節約術 #JetBrainsIDEテクニック #jbtips

JetBrains IDEをご利用の皆様はAI Assistantを活用していますか?
AI Assistantは、IDEが解析済みのインデックス情報を利用することでソースコードのスキャンを減らし、少ないトークンで高精度な開発ワークフローを実現することができます。
とはいえ、多用しているとAIクレジットの消費が気になるものです。
そこで試していただきたいのが、ローカルモデルの活用です。AI AssistantはGPT、Gemini、ClaudeやGrokなどの著名なモデルを自由に選択できるだけでなく、LM StudioやOllamaといったLLMを手元で手軽に動かせるツールと組み合わせることで、無料でAIを使ったワークフローを実現できます。
ここではLM Studioを使った方法をご紹介します。
LM Studioのインストール
LM Studioは、各種LLMのダウンロード・実行・対話型チャットインターフェース、そして言語モデルサーバの機能を備えた統合ツールです。macOS、Windows、Linuxに各アーキテクチャ別のパッケージ(macOSのIntelアーキテクチャを除く)が提供されており、商用、非商用を問わず無償で利用できます。
インストールは簡単で、例えばmacOSの場合はアプリケーションフォルダへドラッグ&ドロップするだけで完了します。
初回起動時は簡単なセットアップを行います。
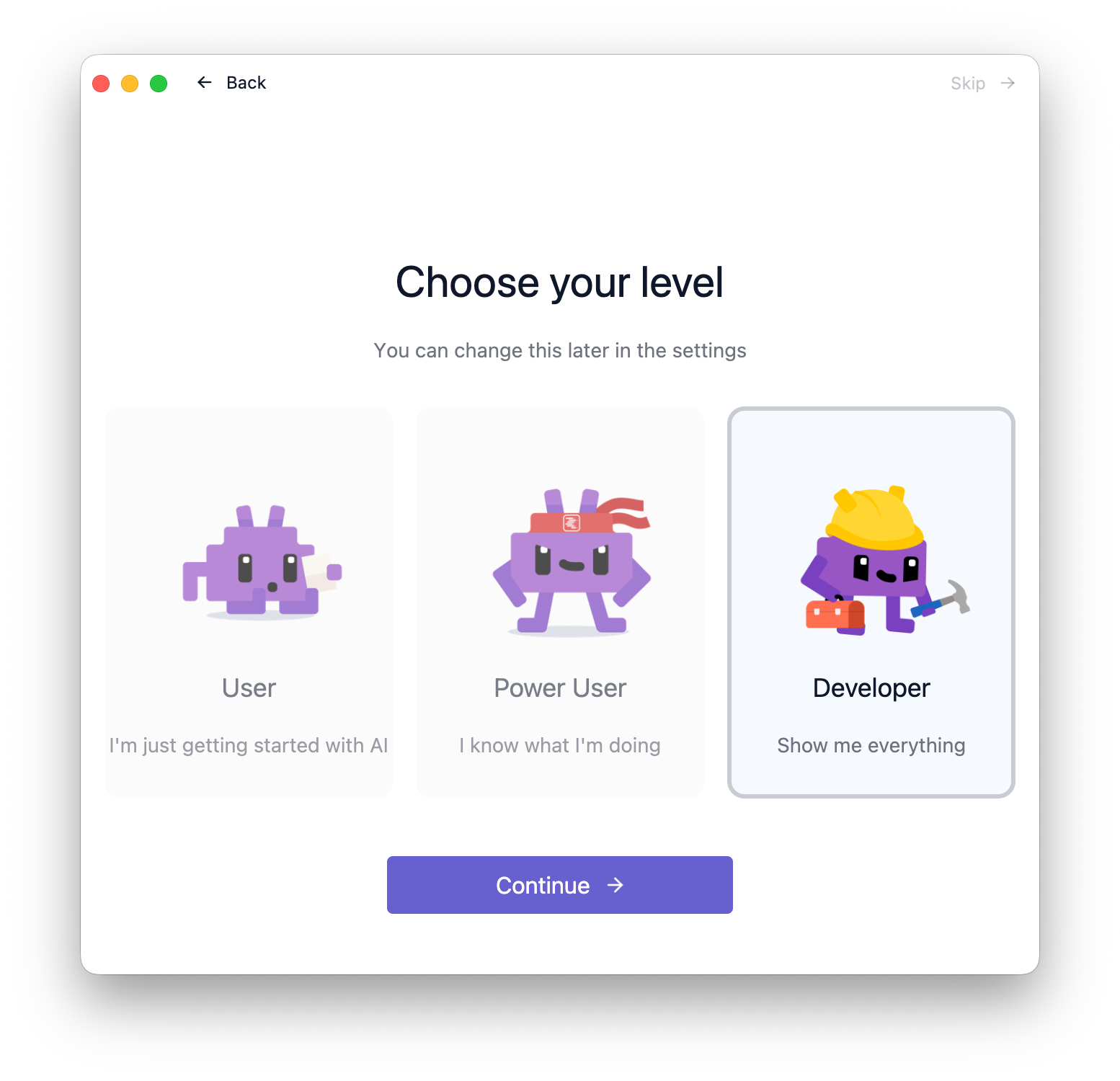
ユーザーのレベルに応じてUIの詳細度が変わる仕組みになっています。プログラマーであれば”Developer”で良いでしょう。このレベルは後からでも1クリックで切り換えられます。
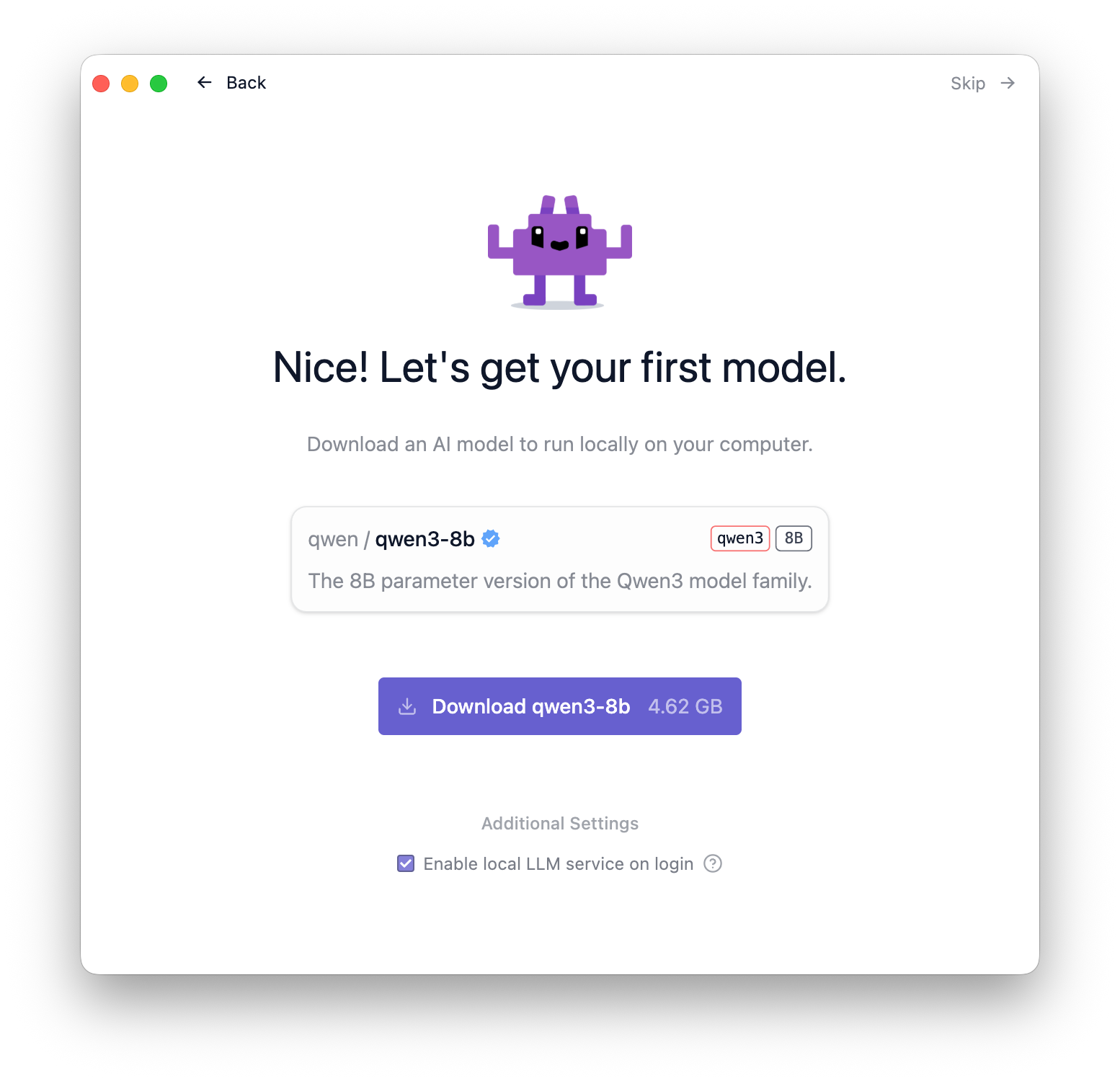
手始めにお勧めのモデルのダウンロードが行えます。ダウンロードボタンを押して進めてください。
ダウンロードが完了したら”Start a New Chat”より、いよいよローカルLLMの動作確認を行えます。
プロンプトを書くとモデルのロードを促すメッセージが現れますので”Model Loader”を押します。
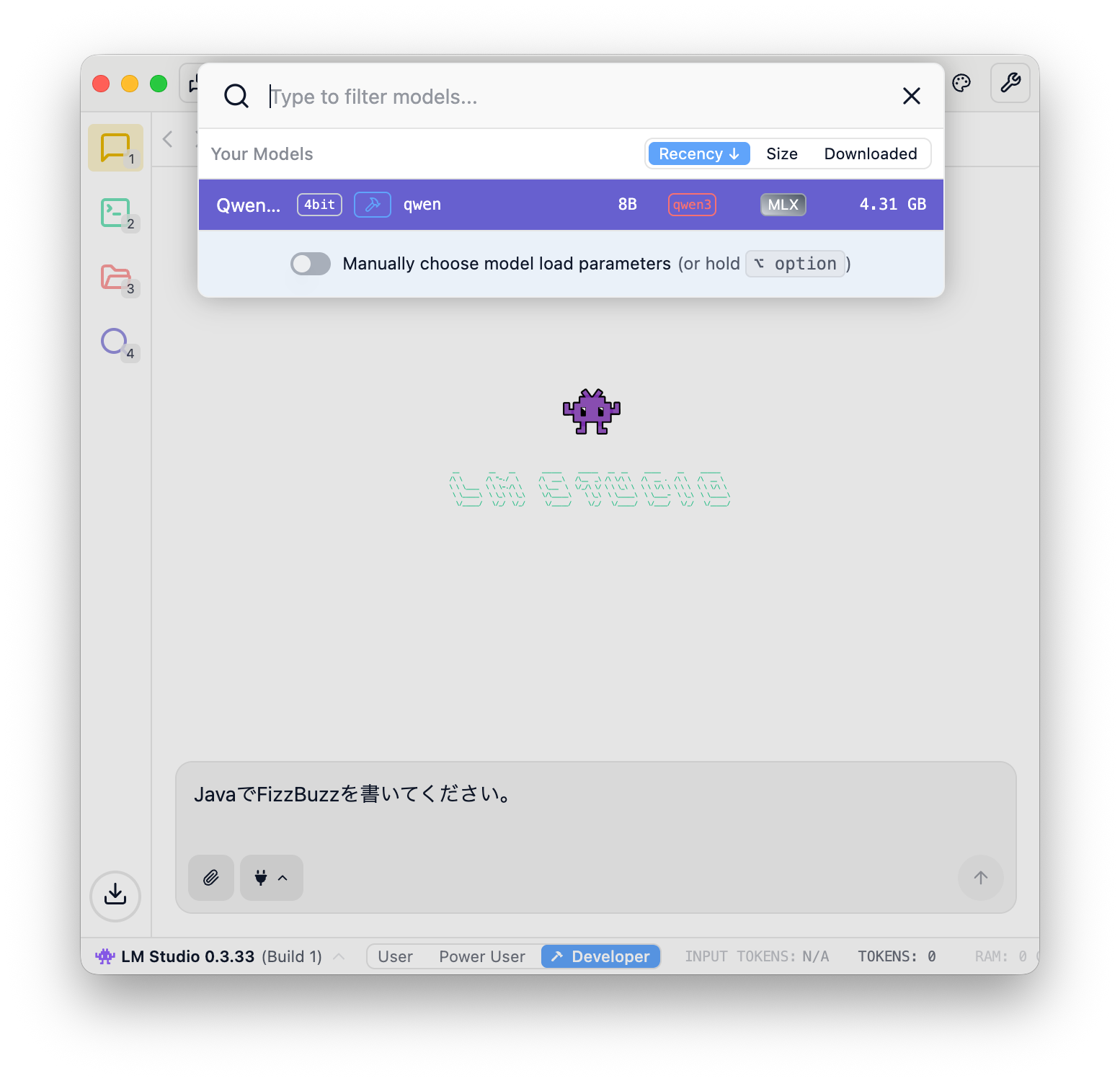
ここでは最初にダウンロードしたQwen3-8bを選択してみます。
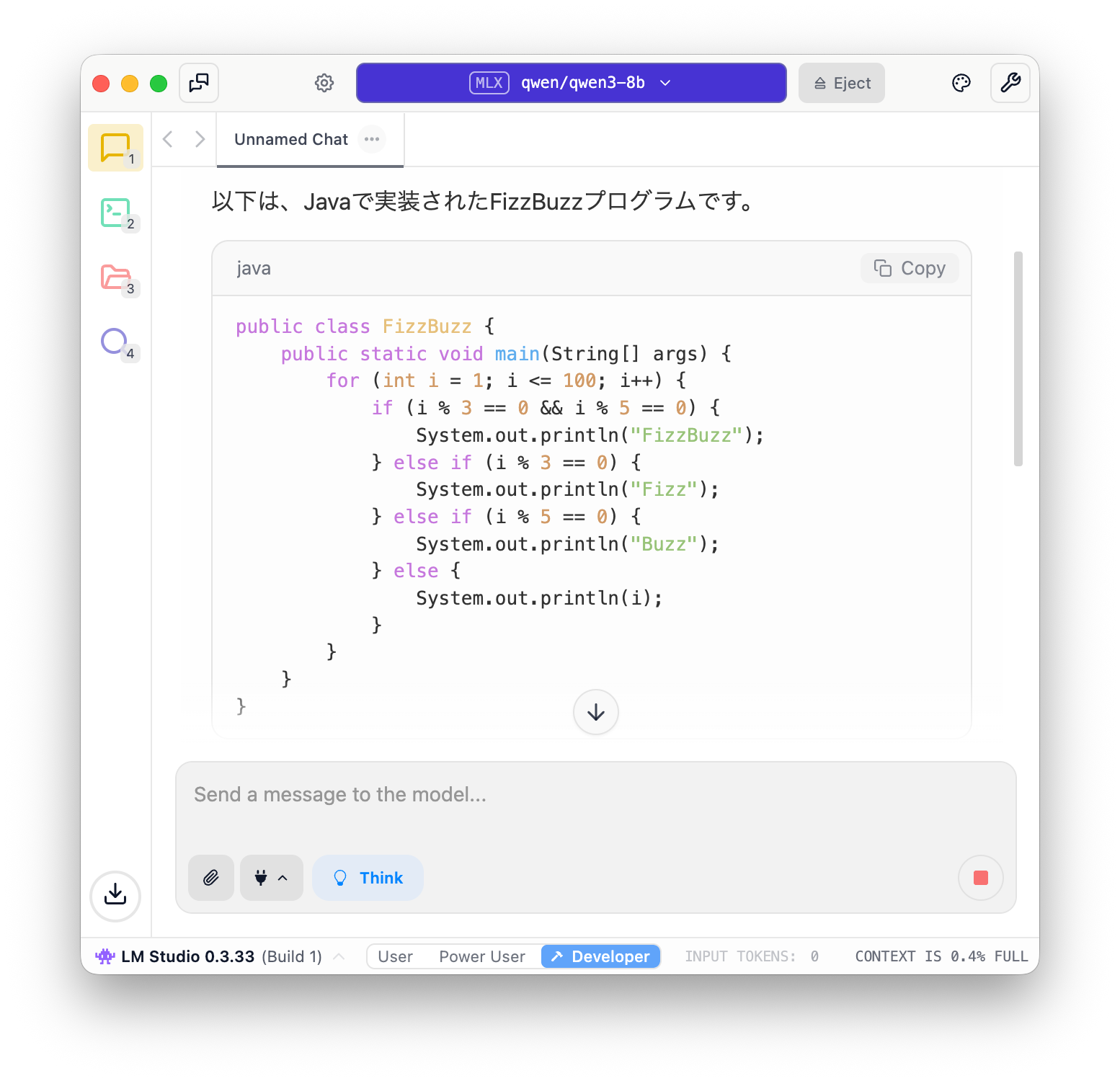
モデルのロードが完了し、プロンプトを投げると、結果が返ってきます。問題無く動作しているようです。
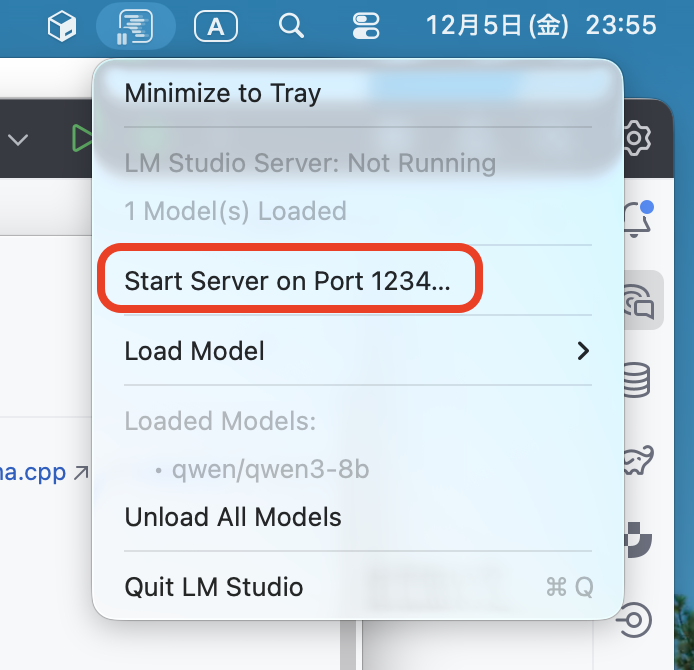
LM Studioのサーバを起動する
次に、LM Studioでロードしたモデルを他のアプリケーションから利用できるよう、サーバを起動します。
macOSではツールメニューから”Start Server on Port 1234…”を選択するだけ起動できます。
AI Assistantの設定
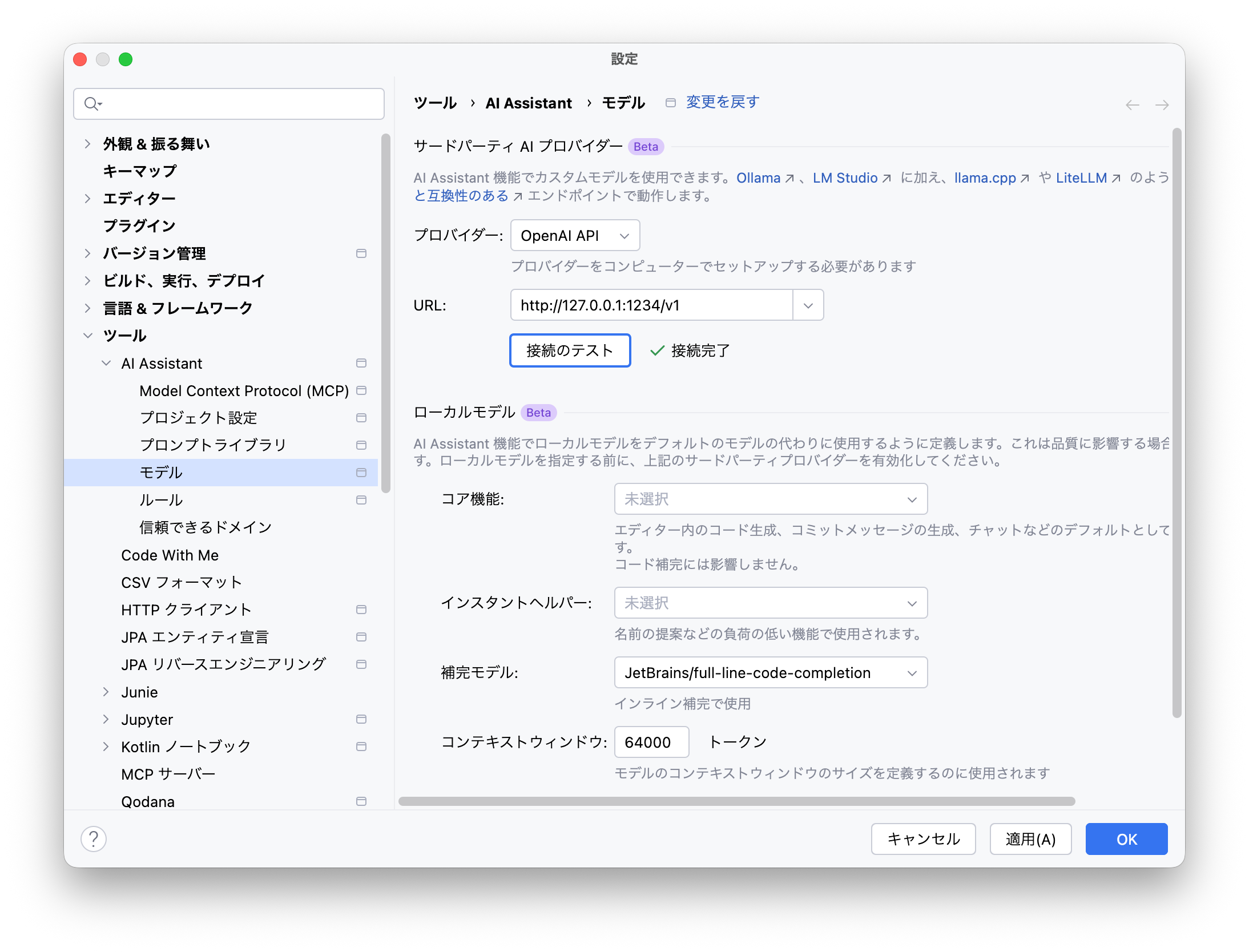
AI AssistantからLM Studioを利用する設定も簡単です。
IDEの設定画面を開き、[ツール]→[AI Assistant]→[モデル]→[サードパーティAIプロバイダー]にて、”OpenAI API”(*)を選択します。
* LM Studioを選択するとチャットUIでモデルを選択できないことがあります
“URL:” 欄には”http://localhost:1234/v1″を入力します。このURLはメニューバーのLM Studioのアイコンより”Copy LLM Server Base URL”でクリップボードにコピーして貼り付けることもできます。
URLの設定まで終わったら[接続のテスト]を押して、[接続完了]となるのを確認しましょう。
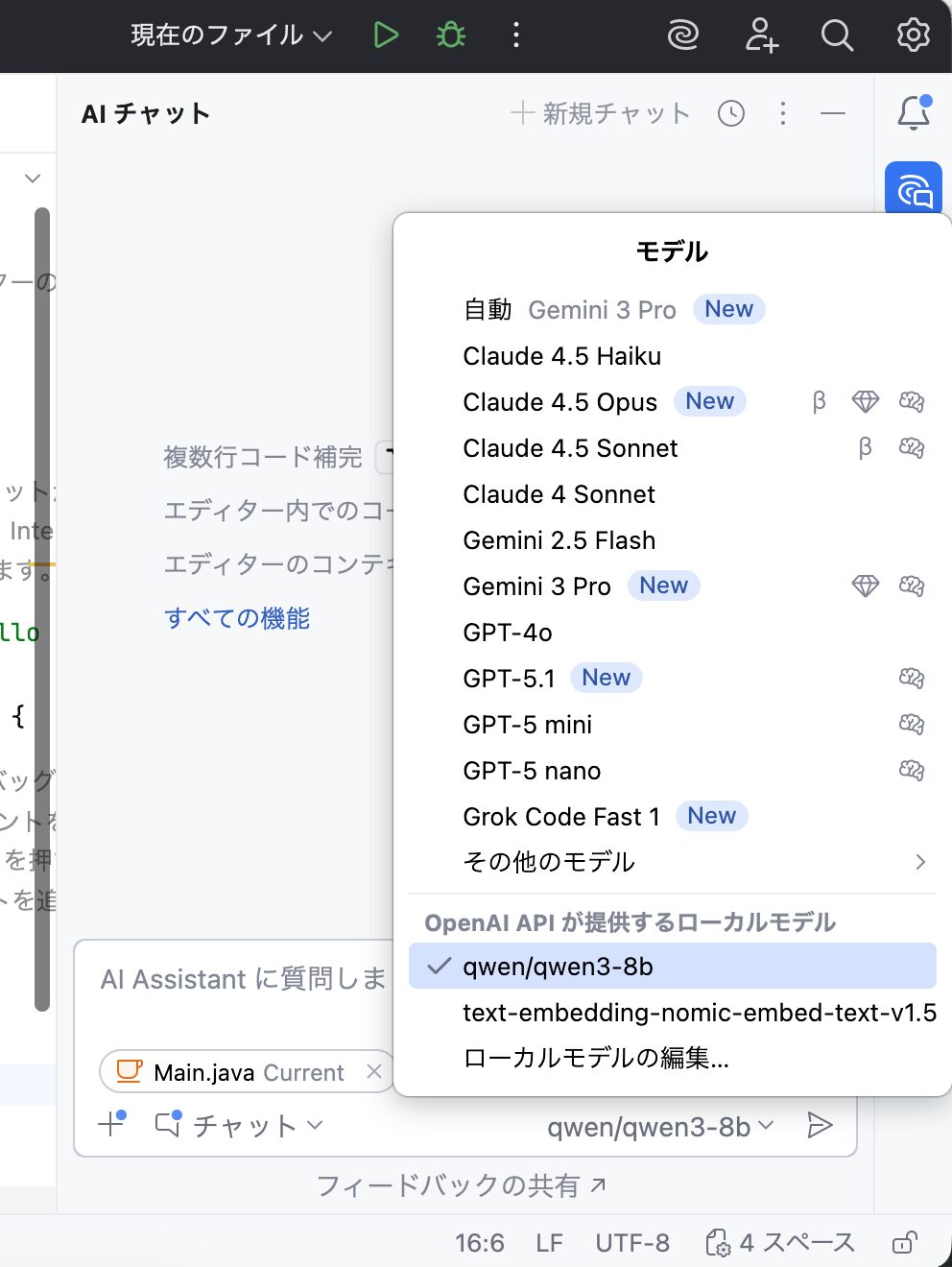
AI Assistantの実行
いよいよAI Assistantで使用するモデルとしてLM Studioを指定します。
AI Assistantのチャットインターフェース右下のモデル選択欄で”OpenAI APIが提供するモデル”より、ローカルで動作するモデルが選べるようになっているのが確認できます。
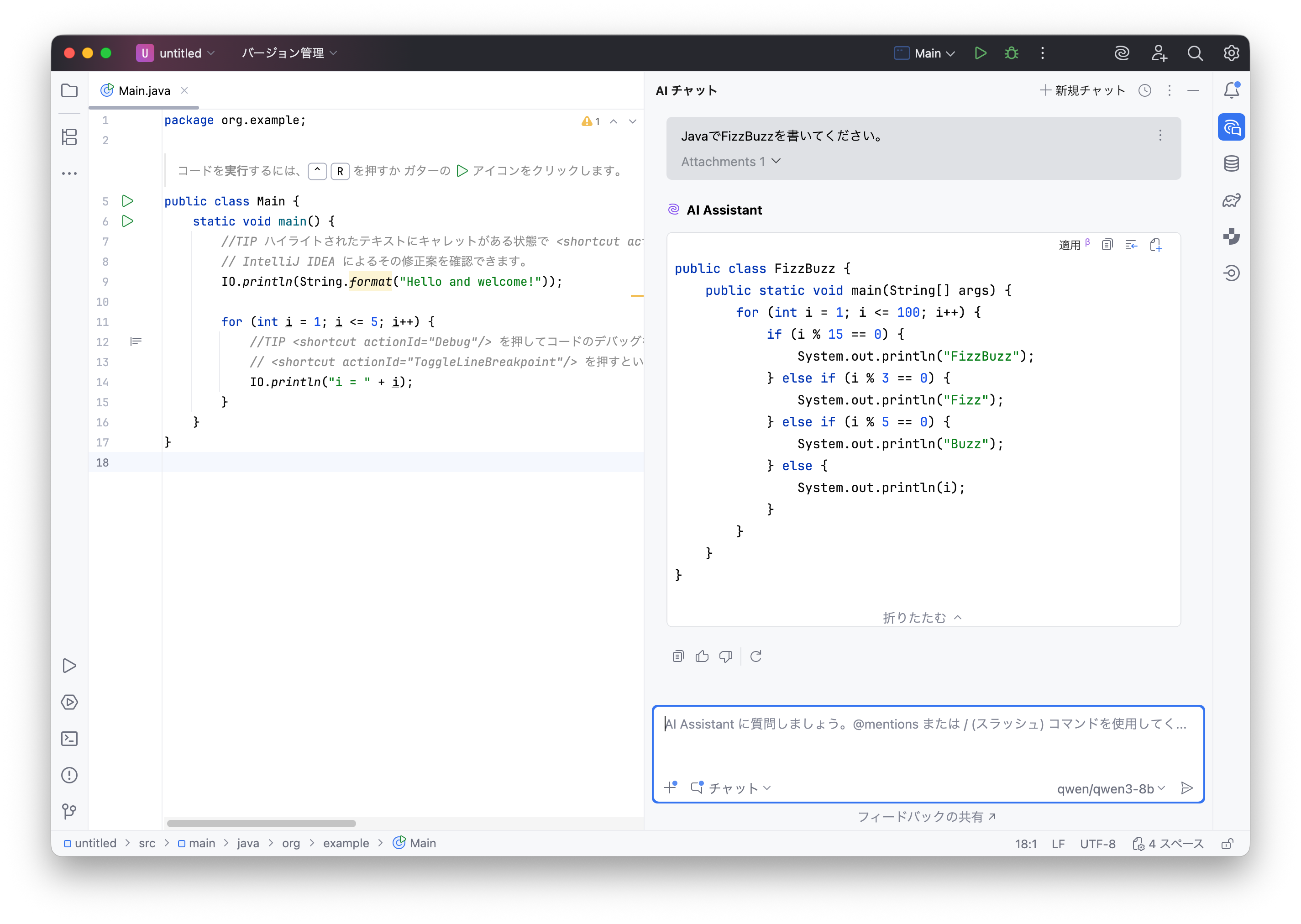
一方、リモートモデルではGPT-5.1-Codexで61秒、GPT-5.1-Codex-Miniでは65秒でした。(計測はどれも1回のみ)
もちろんどの出力もFizzBuzzのプログラムとして正常に動作しました。
動作速度や精度は、利用するモデルの特性や、お手持ちのマシンのメモリ・GPU・CPUによって大きく変化しますが、ローカルLLMでも実用上大きく見劣りすることはなさそうです。普段使いはローカルLLM、複数のバリエーションを高速に試したいときはリモートLLM、といった形で使い分けも可能です。ぜひご活用ください。
Backlog World 2025 に協賛いたします #BacklogWorld

株式会社サムライズムは2025年11月29日にパシフィコ横浜ノースにて開催されるBacklog World 2025に協賛いたします。
サムライズムのブースではJetBrains IDEをBacklogと連携させるBacklog Integration Plugin for JetBrains IDEs、AI Assistant、弊社の生産性向上製品#CIclone、JetBrains IDEに強力なブラウザ機能を追加する#TamaCatなどもご紹介いたします。
ステッカーやピンバッジなどのグッズも配付いたしますので是非お越しください。